The ‘Just One More’ Paradox (student stuff)
12 May, 2024 at 15:50 | Posted in Statistics & Econometrics | Leave a comment.
Here’s a somewhat simplified Python script of the case, and as you can see, the expected median wealth is quickly trending downwards:

Brownian motion (student stuff)
10 May, 2024 at 16:32 | Posted in Economics | 1 Comment.
In case you know some Python you could try this little code snippet and this is the plot you get:

On the art of reading and writing
10 May, 2024 at 12:07 | Posted in Varia | Leave a commentHow should one approach reading? It’s probably a common pondering that everyone has had at some point about our attitude towards literature and reading.
I find reason to contemplate this when my beloved — who tirelessly devours new books at a rapid pace — once again tries to persuade me to put back August Strindberg’s Röda rummet, Hjalmar Söderberg’s Martin Bircks ungdom or Selma Lagerlöf’s Gösta Berlings saga in the library and “try a new book” for once. For her, it’s incomprehensible that anyone would even consider re-reading a novel when there is so much undiscovered and new material to delve into in the wonderful world of literature. For her — and surely many other book enthusiasts — it’s only fools who wholeheartedly engage in constant re-readings.
But let me still try to defend us fools! I’ll turn to a book that I — yes, you guessed it — have read over and over again:
What happens when we read? The eye follows black letters on the white paper from left to right, again and again. And creatures, nature, or thoughts, as another has imagined, recently or a thousand years ago, come to life in our imagination. It is a miracle greater than a grain of wheat from the pharaohs’ tombs being able to sprout. And it happens every moment …
When we read for the second time, it’s like reading a biography of death or seeing our life just before we leave it. Now it becomes clear why that experience in the first chapter made such a strong impression on the heroine. It actually determined her life. A pattern emerges. What was incomprehensible becomes simple and understandable.
Now we can also, just as we do when we remember our own lives, pause at particularly beautiful and meaningful passages. We don’t need to rush because we know the continuation. No worry about the future prevents us from enjoying the present.
I have read this book at least once a year since it came out almost forty years ago. And each time, I am filled with the same joy and wonder. These ninety pages filled with wisdom and contemplation are so infinitely more valuable than all the overly hyped nonsense that is pumped out in today’s increasingly commercialized book market.
When it comes to the art of writing, Lagercrantz’s book has meant a lot to yours truly. Raised in the German-Danish ‘capital-logic’ school of the 1970s and 1980s — Hans-Jörgen Schanz, Hans-Jürgen Krahl, et alii — I was for long of the opinion that sentences shorter than two or three pages could not possibly contain anything of value. Reading Lagercrantz’s book was a revolution for me. It was proven that it was possible to write sentences that were no more than one or two lines long without losing content and coherence.
Thank you, Olof!
Keynes — en ständigt aktuell inspiration
9 May, 2024 at 18:45 | Posted in Economics | 1 Comment
I veckans avsnitt av Starta Pressarna diskuterar yours truly tillsammans med Max Jerneck och Daniel Suhonen varför John Maynard Keynes räknas som 1900-talets kanske främste nationalekonom och hur vi kan vi använda hans idéer för att finna lösningar på dagens samhällsekonomiska problem.
Minnen som glömskan inte rår på
6 May, 2024 at 23:15 | Posted in Varia | Leave a comment.
Marcel Proust hade sin Madeleinekaka. Jag har min musik.
Den här låten är för mig alltid förknippad med sommarminnen på 70-talet från Hästveda och Luhrsjön, där jag och kompisen Johan/Jenny brukade spela flipper vid strandcaféet och den här låten gick varm på jukeboxen.
Minnen som fortfarande värmer.
Minnen som glömskan inte rår på.

The total incompetence of people in charge of the US economy
6 May, 2024 at 12:45 | Posted in Economics | 2 Comments.
Absolutely gobsmacking! Jared Bernstein — the chair of the United States Council of Economic Advisers — obviously needs some good advice about the way monetary systems work. Here’s a book he could start his educational tour with:

Ergodicity — a questionable assumption (wonkish)
5 May, 2024 at 11:08 | Posted in Economics | 1 Comment.
Paul Samuelson once famously claimed that the ‘ergodic hypothesis’ is essential for advancing economics from the realm of history to the realm of science. But is it really tenable to assume — as Samuelson and most other mainstream economists — that ergodicity is essential to economics?
Sometimes ergodicity is mistaken for stationarity. But although all ergodic processes are stationary, they are not equivalent.
Let’s say we have a stationary process. That does not guarantee that it is also ergodic. The long-run time average of a single output function of the stationary process may not converge to the expectation of the corresponding variables — and so the long-run time average may not equal the probabilistic (expectational) average.
Say we have two coins, where coin A has a probability of 1/2 of coming up heads, and coin B has a probability of 1/4 of coming up heads. We pick either of these coins with a probability of 1/2 and then toss the chosen coin over and over again. Now let H1, H2, … be either one or zero as the coin comes up heads or tales. This process is obviously stationary, but the time averages — [H1 + … + Hn]/n — converges to 1/2 if coin A is chosen, and 1/4 if coin B is chosen. Both these time averages have a probability of 1/2 and so their expectational average is 1/2 x 1/2 + 1/2 x 1/4 = 3/8, which obviously is not equal to 1/2 or 1/4. The time averages depend on which coin you happen to choose, while the probabilistic (expectational) average is calculated for the whole “system” consisting of both coin A and coin B.
Instead of arbitrarily assuming that people have a certain type of utility function — as in mainstream theory — time average considerations show that we can obtain a less arbitrary and more accurate picture of real people’s decisions and actions by basically assuming that time is irreversible. When our assets are gone, they are gone. The fact that in a parallel universe, it could conceivably have been refilled, is of little comfort to those who live in the one and only possible world that we call the real world.
Time average considerations show that because we cannot go back in time, we should not take excessive risks. High leverage increases the risk of bankruptcy. This should also be a warning for the financial world, where the constant quest for greater and greater leverage — and risks — creates extensive and recurrent systemic crises.
Suppose I want to play a game. Let’s say we are tossing a coin. If heads come up, I win a dollar, and if tails come up, I lose a dollar. Suppose further that I believe I know that the coin is asymmetrical and that the probability of getting heads (p) is greater than 50% – say 60% (0.6) – while the bookmaker assumes that the coin is totally symmetric. How much of my bankroll (T) should I optimally invest in this game?
A strict mainstream utility-maximizing economist would suggest that my goal should be to maximize the expected value of my bankroll (wealth), and according to this view, I ought to bet my entire bankroll.
Does that sound rational? Most people would answer no to that question. The risk of losing is so high, that I already after a few games played — the expected time until my first loss arises is 1/(1-p), which in this case is equal to 2.5 — with a high likelihood would be losing and thereby become bankrupt. The expected-value maximizing economist does not seem to have a particularly attractive approach.
So what are the alternatives? One possibility is to apply the so-called Kelly criterion — after the American physicist and information theorist John L. Kelly, who in the article A New Interpretation of Information Rate (1956) suggested this criterion for how to optimize the size of the bet — under which the optimum is to invest a specific fraction (x) of wealth (T) in each game. How do we arrive at this fraction?
When I win, I have (1 + x) times as much as before, and when I lose (1 – x) times as much. After n rounds, when I have won v times and lost n – v times, my new bankroll (W) is
(1) W = (1 + x)v(1 – x)n – v T
(A technical note: The bets used in these calculations are of the “quotient form” (Q), where you typically keep your bet money until the game is over, and a fortiori, in the win/lose expression it’s not included that you get back what you bet when you win. If you prefer to think of odds calculations in the “decimal form” (D), where the bet money typically is considered lost when the game starts, you have to transform the calculations according to Q = D – 1.)
The bankroll increases multiplicatively — “compound interest” — and the long-term average growth rate for my wealth can then be easily calculated by taking the logarithms of (1), which gives
(2) log (W/ T) = v log (1 + x) + (n – v) log (1 – x).
If we divide both sides by n we get
(3) [log (W / T)] / n = [v log (1 + x) + (n – v) log (1 – x)] / n
The left-hand side now represents the average growth rate (g) in each game. On the right-hand side, the ratio v/n is equal to the percentage of bets that I won, and when n is large, this fraction will be close to p. Similarly, (n – v)/n is close to (1 – p). When the number of bets is large, the average growth rate is
(4) g = p log (1 + x) + (1 – p) log (1 – x).
Now we can easily determine the value of x that maximizes g:
(5) d [p log (1 + x) + (1 – p) log (1 – x)]/d x = p/(1 + x) – (1 – p)/(1 – x) =>
p/(1 + x) – (1 – p)/(1 – x) = 0 =>
(6) x = p – (1 – p)
Since p is the probability that I will win, and (1 – p) is the probability that I will lose, the Kelly strategy says that to optimize the growth rate of your bankroll (wealth) you should invest a fraction of the bankroll equal to the difference of the likelihood that you will win or lose. In our example, this means that I have in each game to bet the fraction of x = 0.6 – (1 – 0.6) ≈ 0.2 — that is, 20% of my bankroll. Alternatively, we see that the Kelly criterion implies that we have to choose x so that E[log(1+x)] — which equals p log (1 + x) + (1 – p) log (1 – x) — is maximized. Plotting E[log(1+x)] as a function of x we see that the value maximizing the function is 0.2:

The optimal average growth rate becomes
(7) 0.6 log (1.2) + 0.4 log (0.8) ≈ 0.02.
If I bet 20% of my wealth in tossing the coin, I will after 10 games on average have 1.0210 times more than when I started (≈ 1.22).
This game strategy will give us an outcome in the long run that is better than if we use a strategy building on the mainstream theory of choice under uncertainty (risk) – expected value maximization. If we bet all our wealth in each game we will most likely lose our fortune, but because with low probability we will have a very large fortune, the expected value is still high. For a real-life player – for whom there is very little to benefit from this type of ensemble average – it is more relevant to look at the time average of what he may be expected to win (in our game the averages are the same only if we assume that the player has a logarithmic utility function). What good does it do me if my tossing the coin maximizes an expected value when I might have gone bankrupt after four games played? If I try to maximize the expected value, the probability of bankruptcy soon gets close to one. Better then to invest 20% of my wealth in each game and maximize my long-term average wealth growth!
When applied to the mainstream theory of expected utility, one thinks in terms of a “parallel universe” and asks what is the expected return of an investment, calculated as an average over the “parallel universe”? In our coin toss example, it is as if one supposes that various “I” are tossing a coin and that the loss of many of them will be offset by the huge profits one of these “I” does. But this ensemble average does not work for an individual, for whom a time average better reflects the experience made in the “non-parallel universe” in which we live.
The Kelly criterion gives a more realistic answer, where one thinks in terms of the only universe we actually live in, and asks what the expected return of an investment — calculated as an average over time — is.
Since we cannot go back in time — entropy and the “arrow of time ” make this impossible — and the bankruptcy option is always at hand (extreme events and “black swans” are always possible) we have nothing to gain from thinking in terms of ensembles and “parallel universe.”
Actual events follow a fixed pattern of time, where events are often linked in a multiplicative process (e.g. investment returns with “compound interest”) which is basically non-ergodic.
Instead of arbitrarily assuming that people have a certain type of utility function – as in mainstream theory – the Kelly criterion shows that we can obtain a less arbitrary and more accurate picture of real people’s decisions and actions by basically assuming that time is irreversible. When the bankroll is gone, it’s gone. The fact that in a parallel universe, it could conceivably have been refilled, is of little comfort to those who live in the one and only possible world that we call the real world.
Our coin toss example can be applied to more traditional economic issues. If we think of an investor, we can basically describe his situation in terms of our coin toss. What fraction (x) of his assets (T) should an investor – who is about to make a large number of repeated investments – bet on his feeling that he can better evaluate an investment (p = 0.6) than the market (p = 0.5)? The greater the x, the greater the leverage. But also – the greater is the risk. Since p is the probability that his investment valuation is correct and (1 – p) is the probability that the market’s valuation is correct, it means the Kelly criterion says he optimizes the rate of growth on his investments by investing a fraction of his assets that is equal to the difference in the probability that he will “win” or “lose.” In our example this means that he at each investment opportunity is to invest the fraction of x = 0.6 – (1 – 0.6), i.e. about 20% of his assets. The optimal average growth rate of investment is then about 2 % (0.6 log (1.2) + 0.4 log (0.8)).
Kelly’s criterion shows that because we cannot go back in time, we should not take excessive risks. High leverage increases the risk of bankruptcy. This should also be a warning for the financial world, where the constant quest for greater and greater leverage — and risks – creates extensive and recurrent systemic crises. A more appropriate level of risk-taking is a necessary ingredient in a policy to curb excessive risk-taking.
The works of people like Ollie Hulme and Ole Peters at London Mathematical Laboratory show that expected utility theory is transmogrifying truth. Economics needs something different than a theory relying on arbitrary utility functions.
Added 1: If you know some Python, here’s a code you can run to plot and show the difference between a time average and an ensemble average:
import numpy as np
np.random.seed(0)
num_measurements = 200
num_samples = 20
measurements = np.random.randn(num_measurements, num_samples)
time_average = np.mean(measurements, axis=0)
ensemble_average = np.mean(measurements, axis=1)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(time_average, range(num_samples), marker='o')
plt.title('Time Average')
plt.xlabel('Average Value')
plt.ylabel('Ensemble')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(range(num_measurements), ensemble_average, marker='o')
plt.title('Ensemble Average')
plt.xlabel('Measurement')
plt.ylabel('Average Value')
plt.grid(True)
plt.tight_layout()
plt.show()
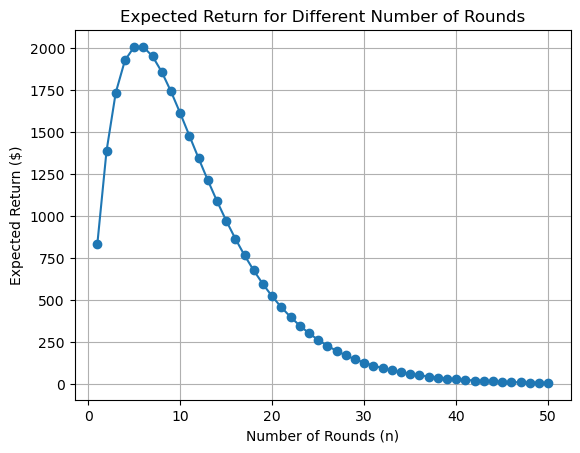
Added 2: And if you're still not convinced it is a bad idea
to always treat things as if they were ergodic, maybe you
should try some Russian Roulette ...
import numpy as np
import matplotlib.pyplot as plt
def play_russian_roulette():
"""
Simulate playing Russian roulette.
Returns:
payoff: The payoff for the game (1000 if survives, 0 otherwise).
"""
if np.random.rand() < 1/6:
return 0
else:
return 1000
def expected_return(n):
"""
Calculate the expected return for a person playing Russian roulette for n rounds.
Args:
n: Number of rounds.
Returns:
exp_return: Expected return.
"""
return (5/6)**n * 1000 * n
def plot_expected_return(max_rounds):
"""
Plot the expected return for each round.
Args:
max_rounds: Maximum number of rounds.
"""
expected_returns = [expected_return(n) for n in range(1, max_rounds + 1)]
plt.plot(range(1, max_rounds + 1), expected_returns, marker='o')
plt.title("Expected Return for Different Number of Rounds")
plt.xlabel("Number of Rounds (n)")
plt.ylabel("Expected Return ($)")
plt.grid(True)
plt.show()
if __name__ == "__main__":
max_rounds = 50
plot_expected_return(max_rounds)
As you will notice the expected return is not very promising ...
Monte Carlo simulation explained (student stuff)
4 May, 2024 at 19:46 | Posted in Statistics & Econometrics | Leave a comment.
Vägval i finanspolitiken
4 May, 2024 at 12:02 | Posted in Economics | Leave a commentI veckans avsnitt av Starta Pressarna fortsätter debatten om det finanspolitiska ramverket
och behovet av stora framtida investeringar i infrastruktur, bostäder, försvar och energiomställning.
Medverkande i det här avsnittet är — förutom Daniel Suhonen — bland annat Lars Calmfors, Elinor Odeberg och Max Jerneck.
Som alltid på den här podden — intressant, slagkraftigt och tankeväckande!
Economics — a dismal and harmful science
1 May, 2024 at 23:07 | Posted in Economics | Leave a comment.
It’s hard not to agree with DeMartino’s critique of mainstream economics — an unethical, irresponsible, and harmful kind of science where models and procedures become ends in themselves, without consideration of their lack of explanatory value as regards real-world phenomena.
Many mainstream economists working in the field of economic theory think that their task is to give us analytical truths. That is great — from a mathematical and formal logical point of view. In science, however, it is rather uninteresting and totally uninformative! The framework of the analysis is too narrow. Even if economic theory gives us ‘logical’ truths, that is not what we are looking for as scientists. We are interested in finding truths that give us new information and knowledge of the world in which we live.
Scientific theories are theories that ‘refer’ to the real world, where axioms and definitions do not take us very far. To be of interest to an economist or social scientist who wants to understand, explain, or predict real-world phenomena, the pure theory has to be ‘interpreted’ — it has to be an ‘applied’ theory. An economic theory that does not go beyond proving theorems and conditional ‘if-then’ statements — and does not make assertions and put forward hypotheses about real-world individuals and institutions — is of little consequence for anyone wanting to use theories to better understand, explain or predict real-world phenomena.
Building theories and models on unjustified patently ridiculous assumptions we know people never conform to, does not deliver real science. Real and reasonable people have no reason to believe in ‘as-if’ models of ‘rational’ robot imitations acting and deciding in a Walt Disney world characterised by ‘common knowledge,’ ‘full information,’ ‘rational expectations,’ zero transaction costs, given stochastic probability distributions, risk-reduced genuine uncertainty, and other laughable nonsense assumptions of the same ilk. Science fiction is not science.
 For decades now, economics students have been complaining about the way economics is taught. Their complaints are justified. Force-feeding young and open-minded people with unverified and useless mainstream economic theories and models cannot be the right way to develop a relevant and realistic economic science.
For decades now, economics students have been complaining about the way economics is taught. Their complaints are justified. Force-feeding young and open-minded people with unverified and useless mainstream economic theories and models cannot be the right way to develop a relevant and realistic economic science.
Most work done in mainstream theoretical economics is devoid of any explanatory interest. And not only that. Seen from a strictly scientific point of view, it has no value at all. It is a waste of time. And as so many have been experiencing in modern times of austerity policies and market fundamentalism — a very harmful waste of time.

Susan Neiman on why left is not woke
30 Apr, 2024 at 13:00 | Posted in Politics & Society | 1 Comment.
As argued by Susan, the universalist ideas of the Enlightenment are still relevant, despite the numerous criticisms that have been levelled against them. The Enlightenment was characterized by a spirit of exploration that led to new discoveries in both science and culture. Rather than promoting a narrow worldview, it encouraged people to question assumptions and religious beliefs. It still provides a framework for addressing some of the most pressing problems facing society, such as climate change and social inequality.



-


Recent Comments
Jan Milch on Keynes — en ständigt akt… rsm on Brownian motion (student … Nanikore on The total incompetence of peop… Bruce Wilder on The total incompetence of peop… rsm on Ergodicity — a questiona… Edward Fullbrook on Susan Neiman on why left is no… rsm on The non-existence of economic… fredtorssander on The non-existence of economic… Mel on Cutting-edge macroeconomics… fredtorssander on MMT — coming to an econo… Jan Milch on The Swedish for-profit ‘… rsm on The Swedish for-profit ‘… fredtorssander on What’s the use of e… rsm on What’s the use of e… fredtorssander on What’s the use of e… Reading List




Blog at WordPress.com.
Entries and Comments feeds.
